
“A couple of years ago, you could not talk to the Google application in the urban noise, or read a sign in a foreign language through an interpreter Google Translate, and instantly find photos of your labradudelya – says Google’s official blog. – Our applications simply were not smart enough. But in a short time they became much, much smarter. Now, thanks to machine learning all that is available. Despite all the progress we have made, still remains room for improvement. Therefore we have created a completely new system of machine learning, called TensorFlow. It’s faster, smarter and more flexible than our old system, so it is much easier to adapt to new products and research. ”
So, Google posted its latest development TensorFlow into the public domain under the freedom of the license Apache 2.0.
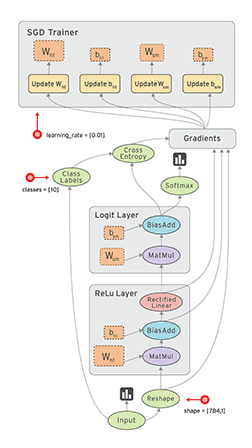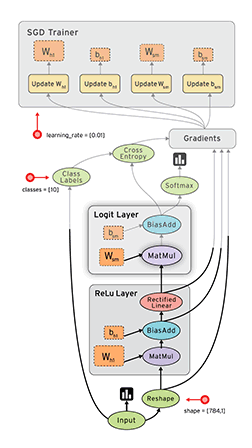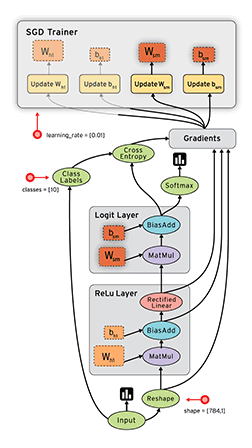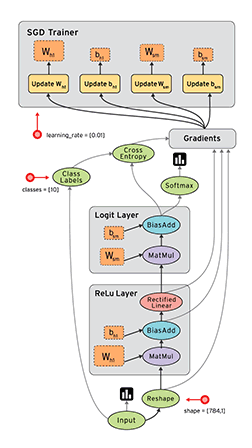
TensorFlow – highly scalable system that can run on a single smartphone, and to thousands of servers in the data center. Google uses TensorFlow almost everywhere, from speech recognition to search for photos in the Google Photos.
New TensorFlow allows you to create and train a neural network to five times faster than the previous generation system DistBelief.
Besides, TensorFlow is not limited to neural networks, and handles large volumes of complex data from protein folding to the array of astronomical data. Any computation that can be expressed in the form of a data flow graph.
Google hopes that with the help of the open library researchers and developers will share operating time not only in the form of scientific articles, but also directly in the form of source code in C ++ or Python. This is further accelerate research in the field of machine learning.
“Machine learning is at an early stage of development – computers still can not understand what the easily capable of four-year child. We have a lot of work ahead. But TensorFlow a good start, and we can all contribute together, “- says Google.